
AI feels magical when it has the right context — and awkward when it doesn’t.
The miracle material is not “intelligence.” It’s context.
Every era gets its miracle material.
Steam turned distance into a rounding error. Steel turned height into a design choice. Semiconductors turned calculation into a commodity.
AI is a stranger material. It doesn’t make matter stronger — it makes thought cheaper. But only when it has something stable to think with.
And that’s where most modern AI experiences quietly break down: the moment your work becomes larger than a chat window.
A brief history of keeping track of what matters
For most of human history, “context” had a physical shape.
Merchants kept ledgers. Scientists kept lab notebooks. Students kept “commonplace books,” where they copied quotes, arguments, and ideas worth reusing. Later we got folders, binders, and those tiny index cards that somehow held entire civilizations together.
The point wasn’t storage. The point was retrieval. When you needed to remember something, you needed a system that could find the right piece at the right time — without dumping the entire library onto your desk.

We’ve always needed systems to filter the noise.
Rearview mirror: why AI still feels like a fancy search box
A lot of our AI workflows are still “driving into the future via the rearview mirror.”
We treat assistants like brighter versions of search. We paste in a pile of notes. We attach ten documents and hope the model “gets it.” We repeat ourselves a week later because the conversation is gone, or the context is stale, or we’re switching between clients.
It works… until it doesn’t. And the failure mode is oddly consistent.
First, context bloat. Too little context makes an assistant sound uninformed. Too much makes it sound oddly distracted, as if it can’t decide what matters.
That’s not a moral failure of the model. It’s just physics: attention is finite, and a big unstructured pile of material doesn’t become clarity just because it’s nearby.
The second missing ingredient is selectivity. What we actually want is not “all my documents.” We want the two paragraphs that matter for this exact question, right now.
Humans do this naturally. We skim, we pattern-match, we bring forward only the relevant pieces. Most AI workflows force us to do the opposite: shovel everything in and pray.
The third missing ingredient is boundaries. There is a growing unease — a reasonable one — about sharing deeply personal or sensitive information with remote systems by default.
Even when the intent is harmless, “just in case context” has a habit of becoming “accidental disclosure.” And once you’ve spilled your private life into a prompt window, it’s hard to feel fully in control again.
“More context” is not the same thing as “better context.”
Individuals: from “document zoo” to personal context
A modern workday produces an absurd number of artifacts.
Meeting notes. Tickets. Drafts. PDFs. Half-finished thoughts. Links you swear you’ll read. Spreadsheets that act like accidental databases. Threads that contain the real decisions, buried between jokes and emojis.
For a while, you can keep it all in your head. Then the pile crosses a threshold. You start doing heavy lifting that looks like work but isn’t the work: explaining your own context back to a system that was supposed to help you.
That’s the moment people start asking for “memory,” “knowledge bases,” and “RAG.” Not because it’s trendy, but because it’s the first honest response to a simple need:
“Stop making me re-teach my own world every time I ask a question.”
What a private knowledge base should feel like (in plain terms)
A private knowledge base is not just “a folder you can search.”
At its best, it behaves more like a good research assistant who has read your material, understands the shape of it, and can pull out the relevant pieces without you micromanaging the process.
To get there, a few principles matter:
- Least-context retrieval. The assistant should receive only what it needs to answer a question, not the full archive.
- Grounding and receipts. When it claims something, it should be able to point back to where it came from — not as a compliance checkbox, but as a trust habit.
- Local control. You should be able to audit what’s stored, delete it, set expiration, and rebuild it without drama.
- Sensitive-by-default handling. The system should assume some material is delicate, and treat it accordingly.
This is where a subtle idea becomes very practical: use local models for protective work.
A smaller model running on your own machine can do the unglamorous jobs: stripping PII, redacting sensitive passages, normalizing formats, and turning messy artifacts into a cleaner “knowledge layer.” Then, when you do call a larger model, you’re sending precision context, not a raw dump.
That’s how you make an assistant feel more potent without making your data feel more exposed.
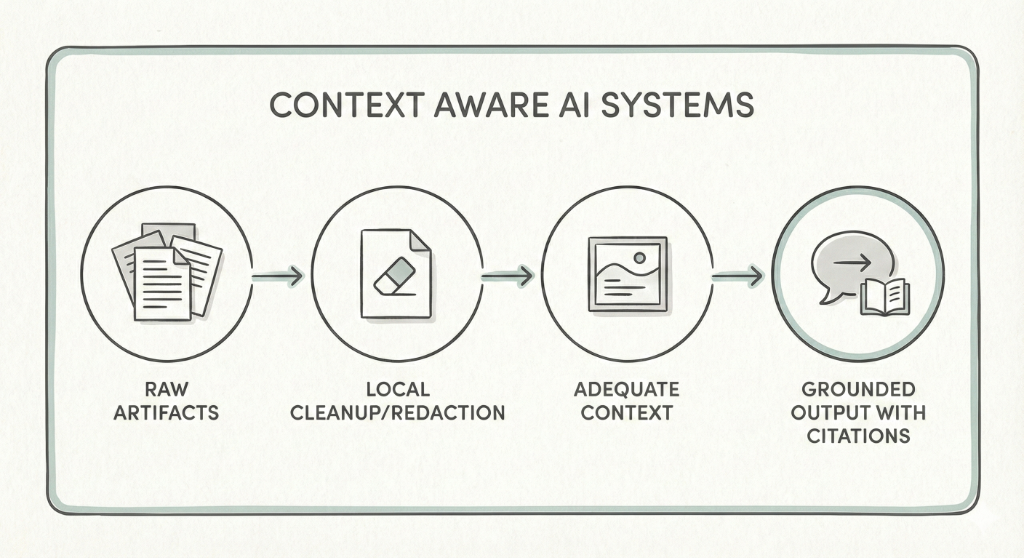
Local models can act as a privacy filter before context leaves your machine.
Organizations: the hidden cost of context debt
In teams, context fragmentation is not just annoying — it’s expensive.
Onboarding becomes a scavenger hunt. Decisions get repeated because the original rationale is lost. People keep private “mental maps” of how things work, and those maps leave when they do.
A knowledge base can help, but only if it’s designed for reality: mixed-quality documents, partial truths, stale notes, and competing versions.
The goal isn’t perfection. The goal is a system that continuously reduces context debt: less re-explaining, fewer mismatches, fewer “wait, which doc is the latest?”
That’s what “knowledge infrastructure” really means.
Economies: when thinking scales, curation becomes the scarce skill
When thinking becomes cheaper, the bottleneck shifts.
We stop being constrained by our ability to generate text, ideas, summaries, plans. We become constrained by our ability to choose what is relevant and trustworthy in a world flooded with information.
In that future, the differentiator won’t be who has the most documents. It will be who can build the cleanest boundary between signal and noise — and do it without leaking what shouldn’t leak.
What we need: private context, without the overshare
Conduit attempts to make “personal context” feel like infrastructure instead of a fragile habit. It helps you build a private knowledge base on your own machine, so your AI utilities can pull just the right supporting details for the task at hand—without you re-explaining everything, and without dumping entire folders into a prompt. The idea is simple: your notes, docs, and artifacts stay under your control, get shaped into something AI can use cleanly, and can be connected to your AI clients with far less setup.
A quiet closing thought

The goal is an assistant that feels personal, not invasive.
Most of us don’t want an assistant that knows everything.
We want an assistant that knows what matters, when it matters, and can show its work — while letting us keep our private world private.
That’s the skyline worth building: an AI experience that feels personal, not invasive. Helpful, not hungry.
Part 1 of 2 in the Conduit series.
Next: Wiring AI without duct tape.